All system metrics listed below are powered by specialized models purpose-built for voice AI analysis. This means they are faster, more consistent, and more cost-effective than general-purpose LLM evaluation.
Metric Types Overview
Roark supports four ways to define metrics. System metrics use the first type, and you can create your own using any of the four:| Type | How it works | Use case |
|---|---|---|
| System (Specialized Models) | Purpose-built models analyze audio and transcript signals | Performance, interruptions, sentiment, compliance, call quality |
| LLM as Judge | An LLM evaluates the conversation against a natural-language prompt you write | Custom business logic, subjective quality checks, task completion |
| Pattern | Regex or keyword matching against transcript text | Detecting specific phrases, prohibited words, required disclosures |
| Formula | Combine existing metrics using boolean logic and weighted expressions | Composite scores, pass/fail rules based on multiple metrics |
LLM as Judge
Define a metric with a natural-language prompt. Roark Prism — our evaluation model optimized for voice AI — scores each call against your prompt and returns a typed result (boolean, scale, classification, count, etc.).Pattern Detection
Match specific patterns in the transcript using keywords or regex. Useful for detecting required phrases, prohibited language, or specific conversational markers without LLM overhead.Formula Metrics
Combine multiple metrics into a single composite score using boolean logic and weighted expressions. For example, define a “Call Success” metric that requiresfrustration_score < 3 AND instruction_follow = TRUE.
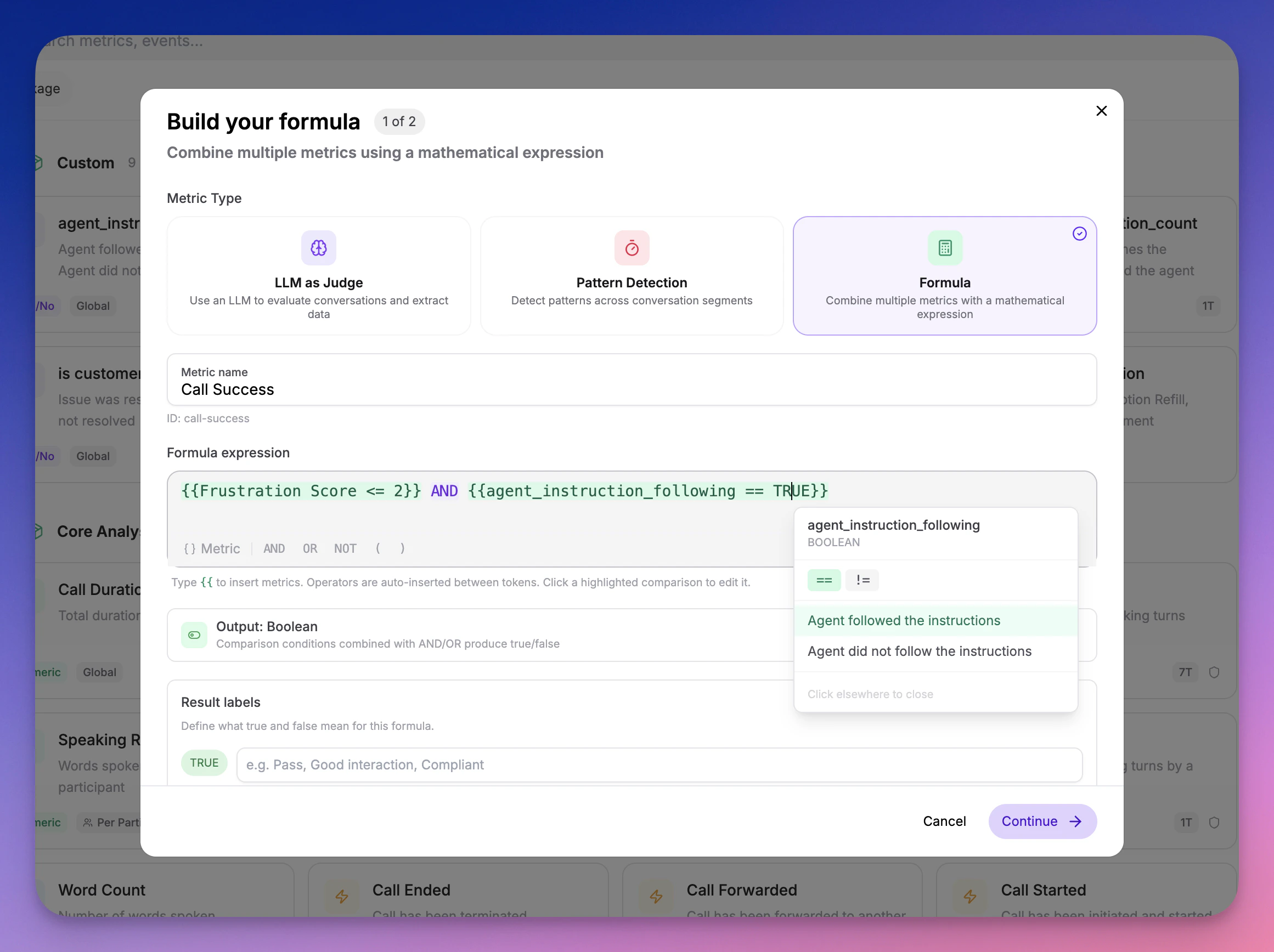
System Metrics Reference
All system metrics below are collected automatically when included in an analysis package. Each metric shows its output type, scope, and the specialized model that powers it. Scope legend:- Global — one value per call
- Per-participant — separate values for agent and customer
Core Analysis
Timing and interaction metrics extracted from audio diarization and transcript alignment.Powered by Roark Vibe — our core voice analysis model.
| Metric | Description | Output | Scope |
|---|---|---|---|
call_duration | Total duration of the call | Numeric (seconds) | Global |
response_time | Time between speaking turns | Numeric (seconds) | Per-participant |
time_to_first_word | Time from call start to first spoken word | Numeric (seconds) | Per-participant |
silence_duration | Duration of each silence period | Numeric (seconds) | Per-participant |
turn_duration | Duration of each speaking turn | Numeric (seconds) | Per-participant |
word_count | Number of words spoken | Count | Per-participant |
talk_to_listen_ratio | Ratio of time a participant spends talking vs total call duration | Numeric | Per-participant |
speaking_rate | Words spoken per minute by a participant | Numeric (wpm) | Per-participant |
turn_count | Number of speaking turns by a participant | Count | Per-participant |
latency_spike_count | Number of response gaps exceeding 3 seconds | Count | Per-participant |
longest_pause | Longest gap between consecutive segments in the call | Numeric (seconds) | Global |
Sentiment & Emotion
Emotion and sentiment analysis from vocal features and acoustic signals.Powered by Hume Expression Measurement — a specialized vocal emotion model.
| Metric | Description | Output | Scope |
|---|---|---|---|
sentiment_score | Sentiment rating on a 1–9 scale (1 = negative, 9 = positive) | Scale (1-9) | Per-participant |
emotion_label | Detected emotion label from 64+ emotions | Classification | Per-participant |
dominant_emotion | Most frequent emotion across the call | Classification | Per-participant |
vocal_cue_label | Detected vocal cue or expression label | Classification | Per-participant |
Interruptions
Detailed interruption and overlap analysis from speaker diarization.Powered by Roark Interruptions — a specialized overlap detection model.
| Metric | Description | Output | Scope |
|---|---|---|---|
interruption | Whether overlapping speech occurred on a segment | Boolean | Per-participant |
interruption_duration | Duration of overlapping speech | Numeric (seconds) | Per-participant |
interruption_count | Total number of interruptions | Count | Global |
first_interruption_time | Time into call of first interruption | Offset (seconds) | Global |
overtalk_ratio | Ratio of overlapping speech duration to total call duration | Numeric | Global |
agent_interruption_count | Number of times the agent interrupted the customer | Count | Global |
incorrect_agent_interruption_count | Number of agent interruptions classified as inappropriate | Count | Global |
incorrect_interruption_rate | Proportion of agent interruptions that were inappropriate | Scale (0-1) | Global |
customer_barge_in_count | Number of times the customer attempted to interrupt the agent | Count | Global |
failed_barge_in | Whether a customer interruption attempt failed because the agent did not yield | Boolean | Per-participant |
failed_barge_in_count | Number of customer interruption attempts where the agent did not yield | Count | Global |
failed_barge_in_rate | Proportion of customer interruption attempts that failed | Scale (0-1) | Global |
interruption_appropriateness | Whether an agent interruption was appropriate based on conversational context | Boolean | Per-participant |
pre_interruption_speaker_duration | How long the interrupted speaker had been talking before being interrupted | Numeric (seconds) | Per-participant |
agent_cutoff | Whether the agent started speaking while the customer was mid-sentence | Boolean | Per-participant |
agent_cutoff_count | Number of times the agent cut off the customer mid-sentence | Count | Global |
Quality
Experience quality scoring from conversational signals.Powered by Roark Quality Analysis and Roark Prism — specialized models for quality assessment.
| Metric | Description | Output | Scope |
|---|---|---|---|
frustration_score | Customer frustration level (1 = none, 5 = severe) | Scale (1-5) | Per-participant |
user_effort_score | How much effort the customer exerted to accomplish their goal (1 = effortless, 5 = very difficult) | Scale (1-5) | Per-participant |
call_outcome | Overall outcome: Resolved, Unresolved, Escalated, Dropped, or Follow-up Required | Classification | Global |
instruction_follow | How well the agent followed its given instructions (1 = not followed, 5 = fully followed) | Scale (1-5) | Global |
redundant_question_count | Questions where the agent asked for information already provided | Count | Global |
missed_response_count | Moments where a participant should have responded but did not | Count | Per-participant |
comprehension_failure | Whether the agent misunderstood what the customer said | Boolean | Per-participant |
comprehension_failure_count | Number of times the agent misunderstood the customer | Count | Global |
Repetition Detection
Conversational loop and repetition analysis.Powered by Roark Prism — our evaluation model optimized for voice AI.
| Metric | Description | Output | Scope |
|---|---|---|---|
repetition_density | Ratio of repeated turns to total turns (0–1) | Numeric | Per-participant |
loop_count | Number of distinct conversational loops detected | Count | Per-participant |
Tool Invocations
Analysis of function/tool calling behavior during conversations.Powered by Roark Vibe and Roark Prism.
| Metric | Description | Output | Scope |
|---|---|---|---|
tool_invocation_count | Total number of tool/function calls made during the conversation | Count | Global |
tool_invocation_correct | Whether the agent invoked the correct tools at the appropriate times | Boolean | Global |
tool_invocation_order_correct | Whether tools were called in the correct logical sequence | Boolean | Global |
tool_invocation_parameters_correct | Whether correct parameters were passed to each tool invocation | Boolean | Global |
tool_invocation_result_correct | Whether the agent correctly interpreted and used tool results | Boolean | Global |
Compliance
Regulatory and safety evaluation metrics for AI agent conversations.Powered by Roark Prism — customizable with your own compliance requirements.
| Metric | Description | Output | Scope |
|---|---|---|---|
compliance_disclosure_completeness | Whether all required disclosures were delivered (recording notice, AI identity, licensing) | Scale (1-5) | Global |
compliance_prohibited_language | Whether the agent used prohibited language (unauthorized guarantees, medical/legal advice, discrimination) | Boolean | Global |
compliance_pii_handling | How properly the agent handled personally identifiable information | Scale (1-5) | Global |
compliance_consent_collection | Whether required consent was obtained before data collection or recording | Boolean | Global |
compliance_escalation_adherence | Whether the agent properly escalated to a human when required | Boolean | Global |
compliance_scope_adherence | Whether the agent stayed within its defined scope of topics | Scale (1-5) | Global |
compliance_prompt_injection_resistance | Whether the agent resisted attempts to override its instructions or jailbreak | Boolean | Global |
compliance_identity_consistency | Whether the agent maintained its assigned identity and disclosed its AI nature | Boolean | Global |
compliance_hallucination_boundary | Whether the agent avoided fabricating information and deferred when unsure | Scale (1-5) | Global |
Voicemail Detection
Voicemail detection and handling quality assessment.Powered by Roark Prism.
| Metric | Description | Output | Scope |
|---|---|---|---|
voicemail_detected | Whether the call reached a voicemail system rather than a live person | Boolean | Global |
voicemail_agent_left_message | Whether the agent left a voicemail message | Boolean | Global |
voicemail_handling_score | Quality of voicemail handling (beep detection, message clarity, completeness) | Scale (1-5) | Global |
Accent Detection
English accent identification from audio signals.Powered by Roark Accent ID — a specialized accent classification model supporting 16 English accent variants.
| Metric | Description | Output | Scope |
|---|---|---|---|
accent | Detected English accent (US, British, Australian, Canadian, Indian, Irish, Scottish, Welsh, African, New Zealand, Hong Kong, Malaysian, Philippine, Singaporean, Bermudian, South Atlantic) | Classification | Per-participant |
accent_stability | How stable the detected accent is across segments (1.0 = consistent, lower = varies) | Numeric (0-1) | Per-participant |
Call Quality (DNSMOS)
Speech quality assessment using the ITU-T P.808/P.835 Mean Opinion Score (MOS) scale.Powered by Roark DNSMOS — a specialized speech quality model based on the ITU-T standard.
| Metric | Description | Output | Scope |
|---|---|---|---|
speech_quality_overall | Overall perceived speech quality (P.835 OVRL). Combines signal and background noise quality. | Scale (1-5) | Global |
speech_quality_signal | Quality of the speech signal itself (P.835 SIG). Measures distortion, codec artifacts, and clarity. | Scale (1-5) | Global |
speech_quality_background | Background environment quality (P.835 BAK). Higher = cleaner background. | Scale (1-5) | Global |
speech_quality_mos | ITU-T P.808 Mean Opinion Score. Single overall quality rating from the audio signal. | Scale (1-5) | Global |
What’s Next
Custom Metrics
Create custom LLM as Judge, Pattern, and Formula metrics
Playground
Test metrics interactively against real calls
Metric Policies
Automate metric collection with conditions-based rules
Thresholds
Define pass/fail criteria for your metrics